Hi there! I've been working on my own operating system since last year. It currently has paging, virtual file system, ramfs, and it can show stuff by writing pixels into a framebuffer. I've always been curious with how Linux, Windows and other operating systems do multitasking. More importantly, how do they switch context?
Trying to learn from OSDev Wiki
In the OSDev Wiki, I found a pretty interesting tutorial on multitasking. It can be found
here. I tried to read through it and understand what's
going on. But, alas! I couldn't understand even 50% of it. I was pretty confused about the implementation of switch_to_task.
But tbh, it was not the OP's fault. The most interesting thing was Thread Control Block. If we look at the code:
1 ;C declaration:
2 ; void switch_to_task(thread_control_block *next_thread);
3 ;
4 ;WARNING: Caller is expected to disable IRQs before calling, and enable IRQs again after function returns
5
6 switch_to_task:
7
8 ;Save previous task's state
9
10 ;Notes:
11 ; For cdecl; EAX, ECX, and EDX are already saved by the caller and don't need to be saved again
12 ; EIP is already saved on the stack by the caller's "CALL" instruction
13 ; The task isn't able to change CR3 so it doesn't need to be saved
14 ; Segment registers are constants (while running kernel code) so they don't need to be saved
15
16 push ebx
17 push esi
18 push edi
19 push ebp
20
21 mov edi,[current_task_TCB] ;edi = address of the previous task's "thread control block"
22 mov [edi+TCB.ESP],esp ;Save ESP for previous task's kernel stack in the thread's TCB
23
24 ;Load next task's state
25
26 mov esi,[esp+(4+1)*4] ;esi = address of the next task's "thread control block" (parameter passed on stack)
27 mov [current_task_TCB],esi ;Current task's TCB is the next task TCB
28
29 mov esp,[esi+TCB.ESP] ;Load ESP for next task's kernel stack from the thread's TCB
30 mov eax,[esi+TCB.CR3] ;eax = address of page directory for next task
31 mov ebx,[esi+TCB.ESP0] ;ebx = address for the top of the next task's kernel stack
32 mov [TSS.ESP0],ebx ;Adjust the ESP0 field in the TSS (used by CPU for for CPL=3 -> CPL=0 privilege level changes)
33 mov ecx,cr3 ;ecx = previous task's virtual address space
34
35 cmp eax,ecx ;Does the virtual address space need to being changed?
36 je .doneVAS ; no, virtual address space is the same, so don't reload it and cause TLB flushes
37 mov cr3,eax ; yes, load the next task's virtual address space
38 .doneVAS:
39
40 pop ebp
41 pop edi
42 pop esi
43 pop ebx
44
45 ret ;Load next task's EIP from its kernel stack
It seems to store some registers, and then loads the TCB of previous task into edi. And then loads
the TCB of next task to esp. And then does some mov's I don't really understand. There are some stuff like
kernel stack and virtual address space that aren't really present in the kernel right now. So, I decided to change
my plan.
Plan B
I started to go through random repositories of fantastic kernels written by fantastic people to try to grasp how they did multitasking. I looked through source code of Lemon OS, Aero OS and many more. One thing they had in common is that the scheduler would do some stuff and then pass the context information to an assembly function. That thing does the actual work of moving and updating all the necessary registers and doing the jump.
But, what about rip? This was a pretty stupid thing done by me tbh. I was trying to find how to update rip directly.
Like, mov rip, rax. I didn't realize that it was impossible. It was possible to read value by using lea.
So, I wasted couple weeks thinking about it. Yeah. But then, today I just found I can do it just by pushing a value
onto stack and running ret. Damn. This easy?
So now I started to implement a basic function that'll take a struct Context and use the values from there
to update the registers.
1 #[derive(Default, Debug, Copy, Clone)]
2 #[repr(packed)]
3 pub struct Context {
4 pub rbx: u64,
5 pub rbp: u64,
6 pub r12: u64,
7 pub r13: u64,
8 pub r14: u64,
9 pub r15: u64,
10 }
Following is the code of the function:
1 #[naked]
2 pub unsafe extern "C" fn switch_context(
3 new_context: &Context,
4 new_cr3: usize,
5 rip: usize,
6 ) {
7 asm!(
8 "\
9 mov rax, rsp
10 mov rsp, rdi
11 pop rbx
12 pop rbp
13 pop r12
14 pop r13
15 pop r14
16 pop r15
17 mov rsp, rax
18 mov cr3, rsi
19 push rdx
20 ret
21 ",
22 options(noreturn)
23 )
24 }
This is a naked function(doesn't have the prologue and epilogue like normal functions do) that takes the context,
cr3(for setting the address space of switched task) and the value for rip. The code basically backs up the stack first,
then sets the pointer to Context as stack pointer. Then we pop the values from it with the same order we declared
the register values in Context. The ordering is very important here. Otherwise, register will get wrong value. Then
it restores original stack, updates cr3. After that, it basically pushes rdx. Why rdx? Well, the "C" calling convention
requires that function arguments are put in following order: rdi, rsi, rdx, rcx, etc. That means, new_context
is stored in rdi, new_cr3 is stored rsi and rip is stored in rdx. After that, we run the ret instruction.
Testing the thing
Let's make a dummy function and call it through this. First, the dummy function:
1 fn test_func() {
2 let rbx: u64;
3 let rbp: u64;
4 let r12: u64;
5 let r13: u64;
6 let r14: u64;
7 let r15: u64;
8
9 unsafe {
10 asm!("\
11 mov {}, rbx\n\
12 mov {}, rbp\n\
13 mov {}, r12\n\
14 mov {}, r13\n\
15 mov {}, r14\n\
16 mov {}, r15\n\
17 ", out(reg) rbx,
18 out(reg) rbp,
19 out(reg) r12,
20 out(reg) r13,
21 out(reg) r14,
22 out(reg) r15);
23 }
24
25 info!("Hello from test func!");
26 info!("Registers: ");
27 info!("rbx = 0x{:x}, rbp = 0x{:x}, r12 = 0x{:x}, r13 = 0x{:x}, r14 = 0x{:x}, r15 = 0x{:x}",
28 rbx, rbp, r12, r13, r14, r15);
29 }
The function basically reads all the registers updated by the context switch function and displays the values.
Let's call switch_context with some values:
1 unsafe {
2 switch_context(
3 &Context {
4 rbp: 0xcafe,
5 rbx: 0xbabe,
6 r12: 0xdeadbeef,
7 r13: 0xfeedbed,
8 r14: 0xfacefeed,
9 r15: 0xfacebace,
10 },
11 Cr3::read().0.start_address().as_u64() as usize,
12 test_func as *const fn() as usize,
13 );
14 }
We are basically setting some interesting values to the registers, setting cr3 to what we are using currently as we can't
set up new page tables now, and then passing the pointer to test_func. The switch_context function doesn't crash and switches
task successfully. Here's the output:
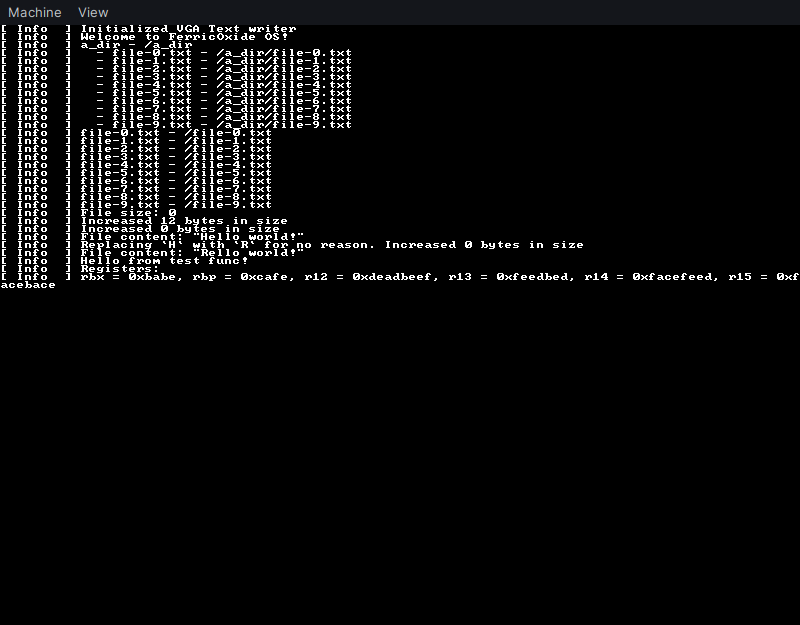
Conclusion
I've learned some stuff about switching context and tried to implement them. Tbh, current one isn't really efficient.
It doesn't really store the context of previous task somewhere, and it's currently a fancy unsafe function caller.
I've plans to make it so that it actually works properly in real multitasking scenario. I'm going to have to write a
scheduler and make it schedule tasks. It can be done through PIC. But that's for next time. Currently, my college
class is going to begin soon, and I'm going to have to study to get into a good university. Till then, stay safe and keep grinding.